
برای شروع آموزش یادگیری عمیق چیکار کنیم؟
آموزش یادگیری عمیق | برای شروع آموزش Deep learning چیکار کنیم؟
در این بخش از وب سایت ایزی بیلد، یک راهنمای جامع برای آموزش یادگیری عمیق به صورت قدم به قدم ارائه میشود. اگر شما یک مبتدی در این حوزه هستید یا میخواهید مفاهیم اصولی را درک کنید، این راهنما به شما کمک میکند تا از پایه به مفاهیم یادگیری عمیق مسلط شوید.
همچنین در صورت تمایل می توانید مقاله آموزش یادگیری با هوش مصنوعی را هم مطالعه کنید.
مفاهیم اولیه یادگیری عمیق
شبکههای عصبی:
شبکههای عصبی مدلهای محاسباتی هستند که به تقلید از ساختار مغز انسان میپردازند. این مفهوم از تعداد بسیار زیادی از واحدهای کوچک به نام نورونها تشکیل شده است.
نورونها:
نورونها واحدهای اصلی در یک شبکه عصبی هستند. هر نورون اطلاعات را از ورودیها دریافت کرده، آنها را پردازش میکند و به خروجی تولید میکند. این خروجی به عنوان ورودی برای نورونهای بعدی در شبکه عصبی عمل میکند.
لایههای شبکه:
شبکههای عصبی به تعدادی لایه تقسیم میشوند. لایههای ورودی دادهها را دریافت میکنند، لایههای مختلف درونی پردازشهای مختلف را انجام میدهند، و لایههای خروجی نتایج نهایی را تولید میکنند. هر لایه میتواند شامل چندین نورون باشد.
وزنها:
وزنها در شبکههای عصبی نقش بسیار مهمی ایفا میکنند. هر اتصال بین نورونها دارای یک وزن است که نشان دهنده اهمیت ورودیها در تولید خروجی است. آموزش شبکه عصبی به معنای بهینهسازی وزنها به گونهای است که مدل عملکرد بهتری داشته باشد.
توابع فعالسازی:
توابع فعالسازی در نورونها استفاده میشوند تا تعیین کنند که آیا یک نورون فعال شود و اطلاعات را منتقل کند یا نه. توابع معمولی شامل توابع سیگموید و تانژانت هستند.
آموزش و یادگیری:
یکی از ویژگیهای جالب شبکههای عصبی، قابلیت آموزش و یادگیری است. شبکههای عصبی با استفاده از دادههای آموزشی قادر به تنظیم و بهبود وزنها و عملکرد خود هستند. این به معنای این است که میتوانند مسائل مختلفی را حل کرده و الگوهای مختلفی را یاد بگیرند.
در کل، شبکههای عصبی به عنوان ابزاری قدرتمند برای حل مسائل پیچیده در حوزههای مختلف شناخته میشوند و در یادگیری عمیق نقش بسیار مهمی ایفا میکنند. این مفهوم اصولی به راهاندازی ماشینهای هوش مصنوعی برای انجام وظایف مختلف و استفاده از هوش مصنوعی پیشرفتهتر کمک کرده است.
آشنایی با مفهوم شبکههای عصبی:
آموزش یادگیری عمیق یک زیرمجموعه مهم از یادگیری ماشینی است که به استفاده از شبکههای عصبی عمیق برای حل مسائل پیچیده میپردازد. در این بخش، مفاهیم اولیه یادگیری عمیق را بررسی میکنیم:
شبکههای عصبی:
شبکههای عصبی مدلهای محاسباتی هستند که به تقلید از ساختار مغز انسان میپردازند. آنها از لایههای متعدد نورونی تشکیل شدهاند که با هم تعامل دارند. لایه ورودی داده را دریافت میکند، لایههای مختلف درونی اقدام به پردازش دادهها میکنند، و لایه خروجی نتایج را تولید میکند.

یادگیری ماشینی:
یادگیری ماشینی یک حوزه از هوش مصنوعی است که به ماشینها امکان یادگیری از دادهها و بهبود عملکرد خود بدون نیاز به برنامهنویسی دستی را میدهد. در یادگیری عمیق، این تکنیکها با استفاده از شبکههای عصبی عمیق به کار میروند.
یادگیری نظارتشده و بدون نظارت:
در یادگیری نظارتشده، مدل با استفاده از دادههای آموزشی که شامل ورودی و خروجی مطلوب هستند، آموزش داده میشود. این مدل سپس قادر به پیشبینی خروجی برای ورودیهای جدید خواهد بود. در یادگیری بدون نظارت، مدل بدون ورودی و خروجی مشخص آموزش میبیند و سعی در کشف الگوها و ساختارهای پنهان در دادهها را دارد.
توابع هزینه و بهینهسازی:
توابع هزینه، معیارهایی هستند که عملکرد مدل را اندازهگیری میکنند. هدف آموزش مدل به گونهای است که تابع هزینه به حداقل برسد. بهینهسازی این توابع با استفاده از الگوریتمهای بهینهسازی انجام میشود.
وزنها و اندازهگیری خطا:
در شبکههای عصبی، وزنها پارامترهایی هستند که به تعیین اهمیت ورودیها در تولید خروجیها کمک میکنند. خطای مدل، اختلاف بین خروجی مدل و خروجی مطلوب برای دادههای آموزشی است که باید کاهش یابد.
بیشبرازش (Overfitting) و کمبرازش (Underfitting):
بیشبرازش وقتی رخ میدهد که مدل برای دادههای آموزشی به شدت بهینهشده باشد و برای دادههای جدید عملکرد بدتری داشته باشد. کمبرازش وقتی رخ میدهد که مدل به دادههای آموزشی هم عملکرد مناسبی نداشته باشد. تکنیکهای اصطکاکی مانند dropout برای کاهش بیشبرازش مورد استفاده قرار میگیرند.
دادههای ورودی و خروجی:
مهمترین قسمت در یادگیری عمیق، دادههای ورودی و خروجی مدل هستند. دادههای ورودی به عنوان اطلاعات ورودی به مدل عمل میکنند و دادههای خروجی نتایج تولیدی توسط مدل هستند. باتوجه به این توضیحات جمع آوری و پیشپردازش دادهها در این مدل نیازمند توجه ویژه است.
انتخاب معماری شبکه:
انتخاب معماری مناسب شبکه عصبی بسیار مهم است و باید به نوع مسئله و حجم دادهها بپردازد. معماریهای مختلف مانند شبکههای عصبی کانولوشنالی برای تصاویر و شبکههای عصبی بازگشتی برای دادههای دنبالهای مورد استفاده قرار میگیرند.
این مفاهیم اولیه به شما ایدهای از مبانی یادگیری عمیق میدهند. برای پیشرفت در این حوزه، باید به عمیقترین جزئیات و تکنیکهای پیشرفتهتر بپردازید، اما این مفاهیم اولیه پایه ای را برای شروع فهمیدن موضوع ارائه میدهند.
تفاوت بین یادگیری عمیق و یادگیری ماشینی سنتی.
یادگیری عمیق و یادگیری ماشینی سنتی دو زیرمجموعه مهم از هوش مصنوعی هستند که در فرآیند یادگیری دادهها و انجام وظایف مختلف استفاده میشوند. این دو دسته از روشها تفاوتهای مهمی دارند که در زییر به آنها اشاره شده است:
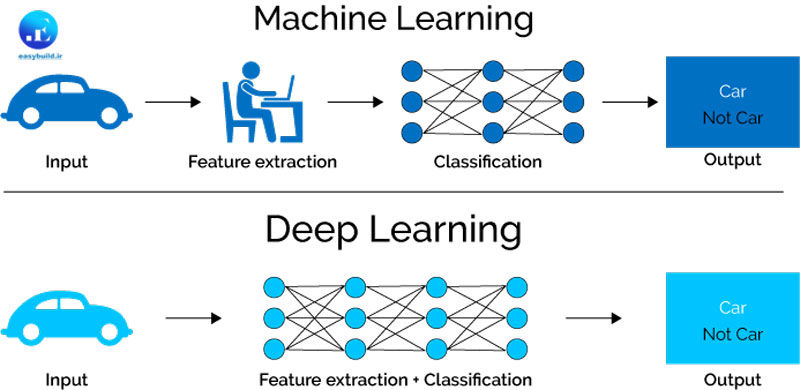
یادگیری ماشینی سنتی:
الگوریتمهای سنتی: در یادگیری ماشینی سنتی، از الگوریتمهای سنتی مانند ماشینهای بردار پشتیبان (SVM)، درخت تصمیم (Decision Trees)، و رگرسیون خطی (Linear Regression) استفاده میشود. این الگوریتمها معمولاً بر اساس قوانین ریاضی و شواهد تجربی ایجاد میشوند.
مهندسی ویژگی: در یادگیری ماشین سنتی، بسیاری از وظایف به مهندسی ویژگیها (Feature Engineering) نیاز دارند. این به معنای انتخاب و تبدیل ویژگیهای مناسب از دادههای ورودی است که میتواند وظیفه را تسهیل کند.
تعیین دستی پارامترها: در این روشها، بسیاری از پارامترهای مدل به صورت دستی تعیین میشوند. این نیاز به تجربه و دانش تخصصی در حوزه انتخاب و جمع آوری درست پارامترهای مختلف به منظور انجام عمل مد نظر ماشین دارد. معمولاً برای آموزش مدلهای یادگیری ماشینی سنتی تعداد دادههای آموزش کمتری نیاز است.
یادگیری عمیق:
شبکههای عصبی عمیق: در یادگیری عمیق، از شبکههای عصبی عمیق (Deep Neural Networks) استفاده میشود. این شبکهها دارای چندین لایه مخفی هستند که به صورت خودکار ویژگیها را از دادهها استخراج میکنند.
تبدیل خودکار ویژگیها: یادگیری عمیق به طور خودکار ویژگیهای مورد نیاز را از دادهها استخراج میکند. این به معنای نیاز کمتر به مهندسی ویژگی است.
تنظیم خودکار پارامترها: در یادگیری عمیق، پارامترهای مدل به صورت خودکار توسط الگوریتمهای بهینهسازی تنظیم میشوند. این به معنای نیاز کمتر به دانش تخصصی در تنظیم پارامترها است. برای آموزش مدلهای یادگیری عمیق، معمولاً تعداد دادههای آموزش بیشتری نیاز است تا مدلها بتوانند از اطلاعات بهتری برای یادگیری استفاده کنند.
تفاوت اصلی بین یادگیری عمیق و یادگیری ماشینی
تفاوت اصلی بین یادگیری عمیق و یادگیری ماشینی سنتی در استفاده از شبکههای عصبی عمیق و امکان خودکارسازی فرآیند یادگیری، در یادگیری عمیق است. این به معنای این است که یادگیری عمیق معمولاً برای مسائل پیچیدهتر و با دادههای بزرگتر موثرتر است و نیاز کمتری به مهندسی ویژگی و تنظیم پارامترها به صورت دستی دارد.
توضیح معماریهای مختلف شبکههای عصبی:
شبکههای عصبی در یادگیری عمیق از معماریهای مختلفی استفاده میکنند که بر اساس نوع مسئله و ویژگیهای داده متناسب با آنها انتخاب میشوند. در ادامه، به تعدادی از معماری معروف شبکههای عصبی اشاره میکنیم:
شبکههای عصبی تغییرپذیر (Feedforward Neural Networks – FNNs):
شبکههای عصبی تغییرپذیر، یکی از سادهترین معماریهای شبکههای عصبی هستند. در این معماری، اطلاعات از لایهی ورودی به صورت تغییرپذیر به لایههای مخفی منتقل میشوند و در نهایت، خروجی تولید میشود. این شبکهها به عنوان یک لایه ورودی از یک یا چند لایه مخفی و یک لایه خروجی تشکیل میشوند.
شبکههای عصبی کانولوشنالی (Convolutional Neural Networks – CNNs):
شبکههای عصبی کانولوشنالی به خصوص برای پردازش تصاویر و دادههای دنبالهای مانند سیگنالهای زمانی طراحی شدهاند. آنها از لایههای کانولوشنال برای شناسایی الگوها و ویژگیهای مکانی در دادههای ورودی استفاده میکنند. CNNs در بسیاری از وظایف بینایی ماشین، تشخیص تصویر، و پردازش تصویر مورد استفاده قرار میگیرند.
شبکههای عصبی بازگشتی (Recurrent Neural Networks – RNNs):
شبکههای عصبی بازگشتی برای پردازش دادههای دنبالهای که به ترتیب وابسته به یکدیگر هستند، طراحی شدهاند. این شبکهها دارای واحدهای بازگشتی هستند که اطلاعات را در حافظه خود نگه میدارند و از آنها برای پیشبینی دادههای آینده استفاده میکنند. RNNs در ترجمه ماشینی، تحلیل متن، و زمینههایی که به ترتیب مهم هستند، مورد استفاده قرار میگیرند.
شبکههای عصبی بازگشتی بلندمدت کوتاه (Long Short-Term Memory – LSTM):
LSTM یک نوع خاص از شبکههای عصبی بازگشتی است که به خصوص برای مسائلی که نیاز به حفظ اطلاعات در طول دنباله دارند، طراحی شدهاند. این معماری از واحدهای خاصی به نام واحدهای LSTM استفاده میکند که به عنوان حافظه کوتاهمدت میانی و حافظه بلندمدت عمل میکنند. LSTM ها در ترجمه ماشینی، پردازش زبان طبیعی، و مسائل دنبالهای مورد استفاده قرار میگیرند.
شبکههای عصبی بازگشتی دوطرفه (Bidirectional Recurrent Neural Networks – BiRNNs):
در این معماری، از دو شبکه عصبی بازگشتی معمولاً با حافظه LSTM استفاده میشود که به صورت دو طرفه اطلاعات را در دنبالهها پردازش میکنند. این به معنای این است که از ابتدا به انتها و از انتها به ابتدا دادهها را پردازش میکنند. BiRNNs در ترجمه ماشینی و تشخیص متن طبیعی کاربردهای زیادی دارند.
شبکههای عصبی با توجه به انتقال (Attention-Based Neural Networks):
این نوع از شبکهها از مکانیزمهای توجه برای تمرکز بر بخشهای مهم دادهها استفاده میکنند. به عبارت دیگر، آنها میتوانند تعیین کنند کدام بخشهای ورودی، بیشترین تاثیر را در تولید خروجی دارند. این شبکهها در ترجمه ماشینی و مسائل پردازش متن مورد استفاده قرار میگیرند.
همچنین باید توجه داشت که معماریهای مختلفی از شبکههای عصبی به صورت ترکیبی نیز مورد استفاده قرار میگیرند تا بتوانند مسائل پیچیدهتر را حل کنند. انتخاب معماری مناسب بسته به شرایط و پیچیدگی های موجود در مسئله برای کاربران امکان پذیر است.
زبانهای برنامهنویسی و کتابخانههای مورد استفاده در آموزش یادگیری عمیق:
زبانهای برنامهنویسی معمولاً ابزارهای اساسی در توسعه مدلهای یادگیری عمیق هستند. یکی از زبانهای برنامهنویسی بسیار محبوب در حوزه یادگیری عمیق، Python است. در ادامه، به برخی از دلایل استفاده از Python و کاربردهای آن در یادگیری عمیق اشاره میشود:

سادگی و خوانایی کد:
Python به عنوان یک زبان بسیار ساده و خوانا شناخته میشود. این به معنای این است که کدهای نوشته شده در Python به راحتی قابل فهم و تغییر دادن هستند. این ویژگی مهمی است زیرا در توسعه مدلهای یادگیری عمیق، اغلب نیاز به آزمایش و تعیین پارامترهای مختلف داریم.
اکوسیستم گسترده:
Python دارای یک اکوسیستم گسترده از کتابخانهها و ابزارهای مرتبط با یادگیری عمیق مانند TensorFlow، PyTorch، Keras، و Scikit-Learn است. این کتابخانهها امکانات مختلفی را برای توسعه مدلهای یادگیری عمیق فراهم میکنند و به توسعهدهندگان این امکان را میدهند تا با سرعت و کارایی بهتر به مسائل خود رسیدگی کنند.
انجام محاسبات پیچیده با سرعت:
Python از زیرساخت NumPy برای انجام محاسبات عددی سریع و پیچیده استفاده میکند. این امکان باعث میشود تا محاسبات ماتریسی و تانسوری معمول در یادگیری عمیق به سرعت انجام شوند. همچنین، بسیاری از کتابخانههای معروف مانند TensorFlow و PyTorch نیز از این زیرساخت بهره میبرند.
جامعیت و توسعه پذیری:
Python به عنوان یک زبان جامع و گسترده شناخته میشود و در زمینههای مختلفی از توسعه نرمافزار مورد استفاده قرار میگیرد. این به معنای این است که توسعهدهندگان میتوانند تجربهها و دانشهای خود را از زمینههای دیگر به یادگیری عمیق انتقال دهند.
جامعه فعال:
Python دارای یک جامعه فعال از توسعهدهندگان و محققان در حوزه یادگیری عمیق است. این به معنای این است که شما میتوانید از تجربیات و کدهای موجود در این جامعه بهرهبرداری کنید و با دیگران در جهان کار کنید.
در نهایت، Python به عنوان یک زبان برنامهنویسی قدرتمند و انعطافپذیر در توسعه مدلهای یادگیری عمیق بسیار مورد توجه است و به دلیل مزایای فوق العادهای که ارائه میدهد، به عنوان ابزار اصلی در این زمینه به شمار میآید.
معرفی کتابخانههای مهم مانند TensorFlow و PyTorch:
کتابخانههای TensorFlow و PyTorch دو مورد از مهمترین و پرکاربردترین کتابخانههای مورد استفاده در آموزش یادگیری عمیق (Deep Learning) هستند. این دو کتابخانه به عنوان ابزارهای اساسی برای توسعه و آموزش مدلهای یادگیری عمیق در پروژههای مختلف استفاده میشوند. در ادامه، به معرفی این دو کتابخانه میپردازیم:
TensorFlow:
تاریخچه: TensorFlow یک کتابخانه متنباز توسعه داده شده توسط تیم مهندسی گوگل است. اولین نسخه آن در سال 2015 منتشر شد و به سرعت به یکی از پرکاربردترین کتابخانههای یادگیری عمیق تبدیل شد.
ویژگیها: TensorFlow دارای ویژگیهای بسیاری از جمله پشتیبانی از انواع مختلفی از لایهها، معماریها و الگوریتمهای یادگیری عمیق است. همچنین از TensorBoard به عنوان ابزار مشاهده و نظارت بر مدلها استفاده می شود.
کاربردها: TensorFlow در کاربردهای متعددی مانند تشخیص تصویر، پردازش متن، ترجمه ماشینی، تحلیل صدا، و بسیاری از حوزههای یادگیری عمیق دیگر مورد استفاده قرار میگیرد.
PyTorch:
تاریخچه: PyTorch نیز یک کتابخانه متنباز است که توسط Facebook توسعه داده شده است. این کتابخانه به عنوان یکی از رقبای قوی TensorFlow در زمینه یادگیری عمیق شناخته میشود.
ویژگیها: PyTorch دارای ویژگیهایی مانند انعطافپذیری بالا، ساختار کد مشابه با Python، و امکانات مختلفی برای تعریف و آموزش مدلهای عمیق است. از جمله ویژگیهای برجسته آن میتوان به Autograd (سیستم محاسبات اتوماتیک گرادیان) اشاره کرد.
کاربردها: PyTorch در کاربردهای یادگیری عمیق مانند پردازش زبان طبیعی، تولید متن، پردازش تصویر و ویدئو، تشخیص صدا، و تحلیل دادههای دنبالهای پیچیده مورد استفاده قرار میگیرد.
انتخاب بین TensorFlow و PyTorch:
انتخاب بین TensorFlow و PyTorch به میزان مورد استفاده، تجربه کاربری، و نیازهای پروژه بستگی دارد. TensorFlow به عنوان یک کتابخانه معتبر و پایدار شناخته میشود و برای پروژههای بزرگ و مهندسی نرمافزار معمولاً مناسب است. در مقابل، PyTorch به عنوان یک کتابخانه انعطافپذیر و منطقی برای آموزش مدلهای عمیق شناخته میشود و برای پژوهشگران و توسعهدهندگانی که به تجربه سریع و آزمایشی علاقه دارند، جذاب است.

در نهایت، انتخاب بین این دو کتابخانه به عنوان ابزار اصلی یادگیری عمیق به عنوان یک موضوع شخصی مطرح میشود و باید بر اساس نیازها و تجربههای خود انجام شود.




